Google Colabで環境構築してstable diffusionで遊んでみた (AMD GPUを使ったローカルでの環境構築中)

2022/12/14追記: ついに動きました
(このページにある情報を参考にするときは自己責任でお願いします)
結果
色々苦戦したけど、最後にはこんな感じのいい感じの絵が出力されました。


環境構築
google colabを使っての環境構築は以下のサイトを参考にしました。
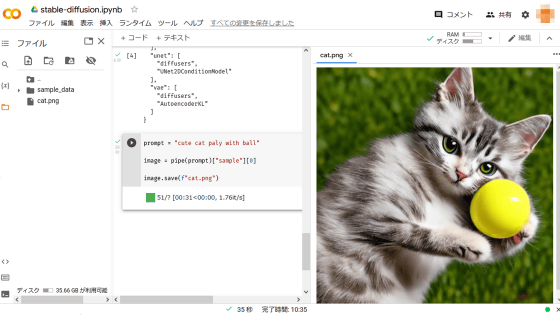
必要な環境構築はたったこれだけという手軽さ(YOUR_TOKENはダミーに置き換えています)

コピペ用
!pip install diffusers==0.2.4 transformers scipy ftfy
YOUR_TOKEN="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" # ここに取得したトークンを入れる
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
pipe.to("cuda")
prompt = "cute cat paly with ball" # ここで出力したい画像を指示する
image = pipe(prompt)["sample"][0]
image.save(f"cat.png")具体的な方法
- google colabでGPUの設定をする
- 上のコードをコピペする
- 実行する
簡単にできました!
おまけ (ローカルで環境構築しようとして失敗した話)
私の環境は以下の通りです
- OS: Ubuntu 20.04
- CPU: Ryzen 5 3600
- GPU: Radeon RX 5700
ローカルでの環境構築方法
探すと日本語の記事がいくつか出てきますが、公式が一番頼りになると思います。
現時点での方法をざっくり解説
- conda環境を作成し、以下のコマンドで仮想環境を作成する
conda env create -f environment.yaml
conda activate ldm- 学習済みパラメータをダウンロードして、リンクを貼る
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt - 出力
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms 実行時にエラーが…
環境構築までは上手くいきましたが、私の環境ではNVIDIA製のGPUを使っていないので、 NVIDIA製のGPUが見つからないよ みたいなエラーが発生しました。(色々奮闘していたのでログは取っていません)
ROCmで対応可能らしい(けどできなかった)
調べていると、AMD製のGPUでもROCmを使うことで動かすことができるケースもあるらしいです。(以下動画参照)
ただ、私の場合はうまく行きませんでした。
navi10 – RX5700XT でROCmを動かす方法
さらに調べると、こちらの方法を使ってROCmを動かせそうだということが分かりました。
が、私は環境構築がうまくできず断念しました。もうpythonの環境がぐちゃぐちゃなので一度最初から作り直そうと思います
結論
AMD GPUで頑張ろうとするのではなく、Google Colabを使いましょう。(でもまだ諦めず挑戦するつもり)
(追記) 動きました!…がうまく画像が生成されない
Ubuntuを20.04から22.04にアップグレードしたので、改めて環境構築に挑戦しました。
22.04にしたことで、返って手間がかかってしまったかもしれませんが、最終的には画像が生成できたので一旦よしとします。(灰色でまだ不完全だけど…)

こちらの記事を参考に試してみました。
エラーその1
最終的にldm環境でサンプルコードを実行したところ、
"hipErrorNoBinaryForGpu: Unable to find code object for all current devices!"と怒られてしまいました。
これは、
export HSA_OVERRIDE_GFX_VERSION=10.3.0
で環境変数を変えてやればOKです。(参考: https://stackoverflow.com/questions/73575955/pytorch-hiperrornobinaryforgpu-unable-to-find-code-object-for-all-current-devi)
エラーその2
メモリ不足で、以下のようなエラーが発生しました。
RuntimeError: HIP out of memory. Tried to allocate 3.00 GiB (GPU 0; 7.98 GiB total capacity; 5.62 GiB already allocated; 2.15 GiB free; 5.77 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF↑の軽量版を利用することで解決
軽量版での環境構築でも同様に、

こちらからrocmでCUDAの環境を上書きします。
私の例では以下のコマンドでうまく行きました。
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.1.1次の課題
無事txt2imgのプログラムの実行は完了したのですが、なぜか画像が灰色になってしまいます。

この問題はまだ解決できていないので、解決でき次第また記事を更新しようと思います。
